Graph Databases
in Big_data / Big Data
The need for data management exists since the dawn of computers. Over the years the need to manage larger and larger amounts of data has emerged. Relational Database Management Systems are mature instruments that can manage millions of records that are efficient in terms of storage. However, SQL complacent databases fall short when the number of records increases dramatically. Historically, data management solutions for Big Data were restrictive and did not implement all SQL functionality. Especially, this concerns joins, which require a lot of storage and computational resources. NoSQL solutions allow people to use the data model that suits their needs more than traditional RDBMS by dropping the requirement for SQL support.
Graph Data Stores
NoSQL and NewSQL
Data management is a critical topic for Big Data. The pressing problem of fast data growth was present as long ago as the 90s, with a common case being storing and analyzing information about transactions. The most popular data model at the time was the Relational Model implemented in RDBMS. The major advantage of RDBMS is the support of SQL query language. SQL is a declarative language that makes the analysis of the data much more accessible.
The field of data management needed horizontal scaling, and large-scale projects such as BigTable and Dynamo served as the proof of concept for scalable databases. The disadvantage of early projects was that they disregard or provide only limited support for complex operations such as joins. Joins over the data partitioned over several servers are extremely expensive. Overall, one of the lessons learned from tackling Big Data is that there are certain tradeoffs between scalability, flexibility, and performance when dealing with large data storage. Several major data models are often distinguished in the field of Big Data:
- Key-Value Stores
- Document Stores
- Wide-Column Stores
- NewSQL
- Graph Databases
The first three categories do not provide support for SQL and provide different levels of performance, consistency, and fault-tolerance based on the particular implementation. Some solutions come with a custom query language. NewSQL is the latest attempt to create scalable databases that provide ACID guaranties. The graph databases, however, offer a different view of the data compared to the relational model and proves to be useful for some applications.
In this task, we focus on graph databases for a couple of reasons. First, the first three categories provide limited query capabilities and are not of great interest. Second, the NewSQL paradigm strives to provide SQL support, and from the user standpoint, is not different from traditional databases from usage standpoint. Graph databases, on the other hand, come with capable query languages that enable complex analysis but are different from SQL.
If you have further interest in the topic of scalable data stores, and the tradeoffs of different implementations, we suggest the following additional reading:
- Scalable SQL and NoSQL Data Stores
- Fast key-value stores: An idea whose time has come and gone
- What’s Really New with NewSQL
- Data management in cloud environments: NoSQL and NewSQL data stores
- Designing Data-Intensive Applications
Graph Databases
Relational databases are great when the schema is predetermined and fixed. However, sometimes, we want to store too many different types of objects in our database, and it becomes simply infeasible to design a schema for every type of object. This is when graph databases become useful. The term relation schema refers to a header paired with a set of constraints defined in terms of that header. Creating a table with a specified schema in SQL: ```sql CREATE TABLE List_of_people ( ID INTEGER, Name CHAR(40), Address CHAR(200), PRIMARY KEY (ID) ) ``` Example: Schema
To leverage data relationships, organizations need a database technology that stores relationship information as a first-class entity. That technology is graph databases.
Most NoSQL databases (and hence Graph databases) were designed at a time when horizontal scaling problem was described and researched well. Some of the SQL databases adopted horizontal scaling as well (such as MySQL - Amazon RDS).
Why relational databases are not enough?
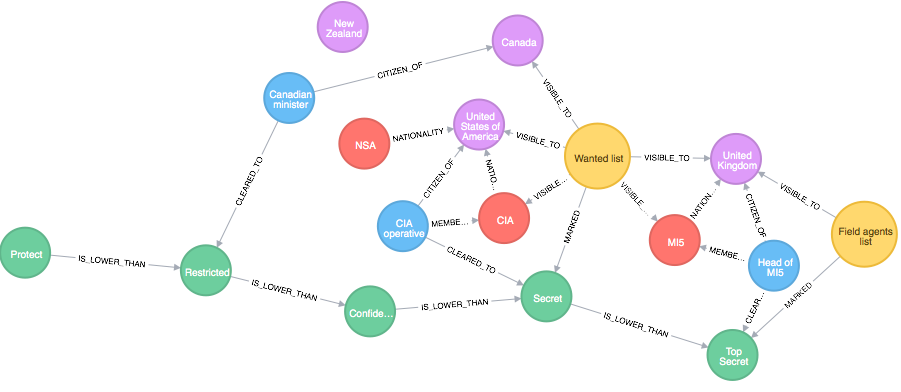
Consider a database with vertexes and relations between them. In many algorithms, we should traverse relationship edges or explore a node neighborhood. Both tasks are hard and inefficient to compute if we store the data in a relational format. SQL queries were not designed to handle iterative computation problems. For example, a query Does a path between node A and node B exist? requires iterative traversal between nodes.
What does index-free adjacency mean?
A graph database is any storage system that provides an index-free adjacency. Technically it means that connected elements are linked together without using an index to avoid expensive operations (such as joins). Remember that index-free adjacency does not imply the absence of an index at all.
Graph Data in Practice
Neo4j
Neo4j is a graph database management system. It is an ACID-compliant transactional database with native graph storage and processing. Neo4j is an OLTP graph database that excels at querying data relationships, which is a weakness of other NoSQL and SQL solutions.
Queries are implemented using graph querying language Cypher.
The installations manuals available in the documentation.
Graph Query Languages
Cypher
This is a short example explaining how to use Neo4j with Cypher query language.
Install and Set Up a New Graph Database
The installation instruction can be found in the official installation manual. For all operating systems, installation boils down to double-clicking the downloaded installer.
After installing, create a new project, a new database, install APOC plug-in. If you wish to repeat the examples below, download the citation dataset, and place it into the import folder. Screenshots



Import Data
Data can be imported into Neo4j using neo4j-desktop browser. Screenshots


LOAD CSV with headers FROM 'file:///nodes.tsv' as row FIELDTERMINATOR '\t'
UNWIND apoc.text.split(row.authors, ",") as authors
CREATE (p:Paper) set p=row, p.year=toInteger(row.year), p.id=toInteger(row.id)
CREATE (a:Author{name:authors})
merge (a)-[:AUTHORS]->(p)
Screenshots


The parentheses () represent a node. Node label is specified with semicolon (:label) Nodes can have properties. Properties are specified by {} inside the node. The properties can be accessed as in p.id. Cypher has some standard functions for data conversion, such as toInteger. UNWIND expands lists into rows (similar to explode). This import statement uses APOC plug-in functions for tokenization. -[:label]-> specifies an edge with given type and direction between nodes. Edges can also have properties {}.
Index important fields right after the import
create index on :Paper(id)
If the dataset is large, transactions need to be batched
CALL apoc.periodic.iterate('
LOAD CSV with headers FROM "file:///edges.tsv" as row FIELDTERMINATOR "\t" return row
','
MATCH (s:Paper{id:toInteger(row.src)})
MATCH (d:Paper{id:toInteger(row.dst)})
MERGE (s)-[:REF]->(d)
',
{batchSize:100}
)
Screenshots

Here, an external function apoc.periodic.iterate is used. It batches the data and performs periodic commits. This becomes important for large datasets. The first argument of the function is the statement that retrieves rows that will be batched. The second statement performs some action over the data. The third argument specifies additional parameters.
Writing Queries
match is an alternative to select from SQL. To select all nodes do
match (n) return n
To get the first 500 nodes write
match (n) return n limit 500
Screenshots


To get nodes with specific label use
match (n:Author) return n
To get nodes with specific properties execute
match (p:Paper{year:2000}) return p
Screenshots

The result will be returned in graph view. You can switch to table view and see that the result is a table that stores JSON objects.
Get the list of most popular venues
match (a:Paper)
return a.venue, count(*) as count order by count desc limit 10
Screenshots

Get the list of most active authors, i.e. authors that participated in the most number of papers
match (a:Author)-[]->()
return a.name, count(*) as count order by count desc limit 10
Screenshots

The first line retrieves all the relationships that match the pattern, where the author is the source node, and it connects with some other node with some relationship. Then, we return the node name and count all the patters that we have found.
Get the list of author-paper pairs that are referenced the most
match (a:Author)-[:AUTHORS]->(p)<-[:REF]-()
return a, p, count(*) as count order by count desc limit 20
Screenshots

Do the same but return a graph of the most cited work
match (a:Author)-[:AUTHORS]->(p)<-[:REF]-()
where size((p)<-[:REF]-()) > 30
return a, p
Screenshots

Get subgraph with only papers that were published on “SIGMOD”
match (a:Author)-[:AUTHORS]->(p)<-[:REF]-()
where size((p)<-[:REF]-()) > 30 and p.venue starts with "SIGMOD"
return a, p
Screenshots

Get a chain of papers from a paper with id 1830 up to 4 citations in the past. Do not forget to index the fields for the year and id for faster performance.
MATCH (c:Paper{year:1999})
MATCH (a:Paper{id:1830})
MATCH p = (c)-[*1..4]->(a)
RETURN p limit 100
Note that if we do not set a limit for this query, the result will be very large, the browser will fail to visualize and will probably freeze.
These are some examples of writing graph queries with cypher. For full usage guide access documentation.
Exporting full query results
Use Cypher shell.
./cypher-shell -u neo4j -p your_pass --file your_query.cql --format verbose > query_output.txt
Additional reading
- Paper where described concepts of Graph DBs
- Comparance of RDBMS and Neo4j in GIS production (rus)
- Citation datasets (1, 2)
- Pagerank Beyond the Web
- Learning from Labeled and Unlabeled Data withLabel Propagation
- The Neo4j Graph Algorithms User Guide
- Scalable SQL and NoSQL Data Stores
- What’s Really New with NewSQL
- Data management in cloud environments: NoSQLand NewSQL data stores
- Designing Data Intensive Applications